
[ad_1]
This publish is part of our weblog sequence on our frontend work. You’ll be able to see the earlier one on “Simplifying Information + AI, One Line of TypeScript at a Time.” and “Constructing the Subsequent Technology Visualization Instruments at Databricks.”
At Databricks, we take the standard of our buyer expertise very critically. As such, we observe many metrics for product reliability. One metric we give attention to is the proportion of classes that see no JavaScript (JS) exceptions. Our aim is to maintain this pleased case above 99.9%, however traditionally, these points have been tracked manually, which for a lot of causes wasn’t ample for conserving errors at bay.
Prior to now, we used Sentry to mixture and categorize a wide range of exceptions, together with these from JS. Sentry each ingests the errors and, on the entrance finish, aggregates sourcemaps to decode minified stack traces.
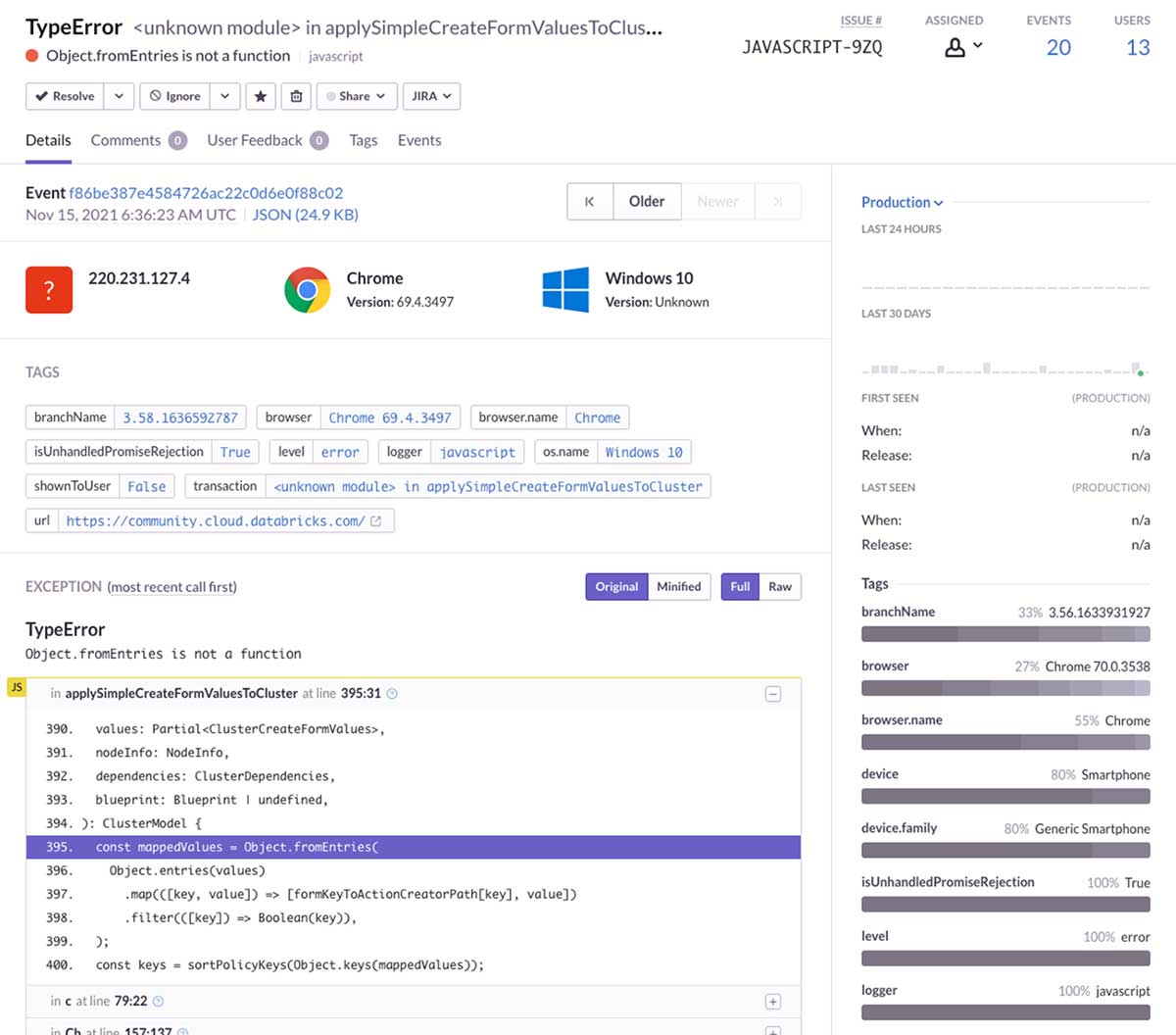
Utilizing Databricks to trace JS exceptions
Whereas contemplating how we may higher automate our exception monitoring and, thus, lower the variety of points being shipped out, we appeared into extending Sentry. Sadly, we discovered that the hassle required was excessive. As we appeared into what Sentry was fixing for our use case, we realized that Databricks’ merchandise may largely accomplish the identical duties, with a better path for extensibility.

First, Databricks is greater than an information platform; it’s basically a general-purpose computing and app infrastructure that sits on high of your knowledge. This allows you to create an ETL the place you ingest every kind of data and apply programmatic transformations, all from throughout the net product.
And when you’ve constructed that ETL, you need to use the outcomes to construct dynamic dashboards, hook up with third-party APIs or the rest. Databricks even has GUIs to orchestrate pipelines of duties and handles alerting when something fails.
With that in thoughts, our problem was to construct an inner, maintainable pipeline for our JS exceptions, with the aim of mechanically creating tickets each time we detected points in staging or manufacturing.
Transferring from Sentry to Databricks
Aggregating into Delta
Step one in developing our ETL was to search out our supply of reality. This was our usage_logs desk, which accommodates all kinds of various logs and metrics for buyer interactions with the product. Each JS exception was saved right here with the minified stack traces.
We began by constructing a Databricks Pocket book to course of our usage_logs. This desk is gigantic and troublesome to optimize, so querying it for exceptions can take thirty minutes or extra. So, we aggregated the info we needed right into a standalone Delta Desk, which enabled us to question and slice the info (roughly a yr’s price of exceptions) in seconds.
Information enrichment: stack hint decoding
Critically, we wanted to discover a technique to decode the minified stack traces in our usage_logs as part of the ETL. This could tell us what file and line brought on a given difficulty and take additional steps to counterpoint the exception based mostly on that data.

Step one right here was to retailer our sourcemaps in an AWS S3 bucket as part of our construct. Databricks helpfully offers you the power to mount S3 buckets into your workspace’s file system, which makes these sourcemaps easily-accessible to our code.
As soon as we had the sourcemaps in S3, we had the power to decode the stack traces on Databricks. This was achieved totally in Databricks Notebooks, which have the power to put in Python libraries through pip. We put in the sourcemap bundle to deal with the decode, then constructed a small Python script to judge a given stacktrace and fetch the related sourcemaps from the file system.

As soon as we had that, we wrapped the script in a UDF in order that we may run it straight from SQL queries in our notebooks! This gave us the power to decode the stack hint and return the file that brought on the error, the road and context of supply code, and the decoded stack itself, all of which have been saved in separate columns.
Code possession
As soon as we decoded the stack traces, we had excessive confidence on which file was liable for every error and will use that to find out which workforce owned the difficulty. To do that, we used Github’s API to crawl the repository, discover the closest OWNERS file and map the proudly owning workforce to a JIRA element.
We constructed this into one other UDF and added it to our aggregator, so when an exception got here in, it was pre-triaged to the right workforce!
Databricks SQL dashboards
To achieve visibility into what was occurring within the product, we used Databricks SQL to construct dashboards for high-level metrics. This helped us visualize traits and captured the fine-grain points occurring within the present launch.
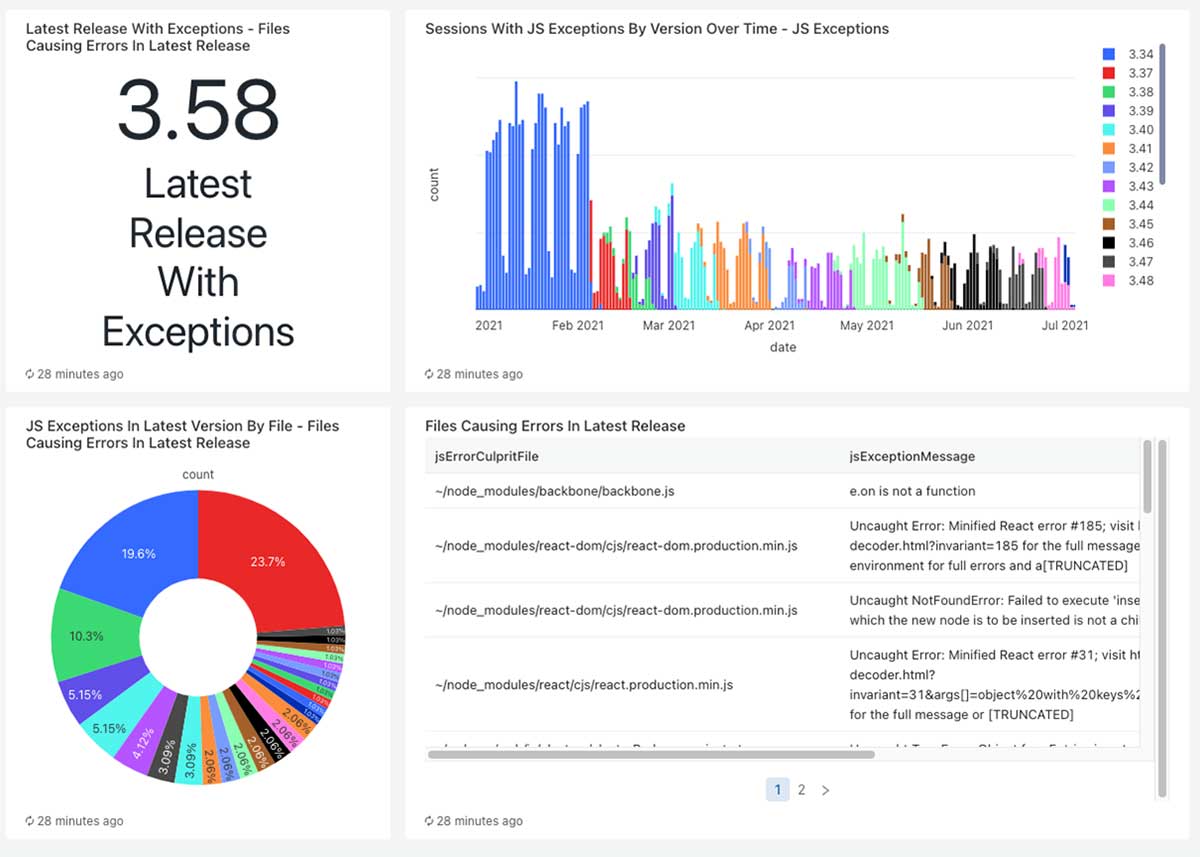
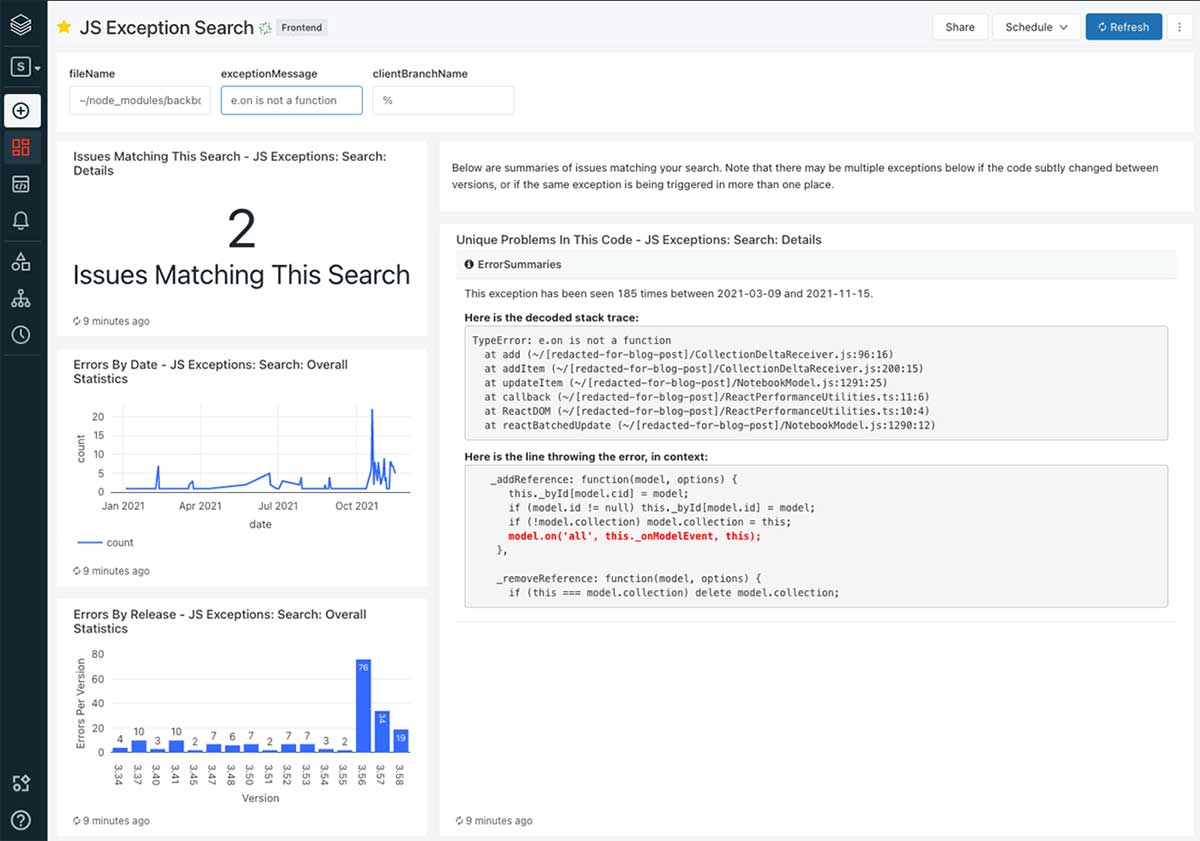
We additionally constructed dashboards for analyzing explicit points, which present error frequency, variations of the error and extra. This, in impact, replaces Sentry’s UI, and we are able to increase it to supply whichever knowledge is probably the most related to our firm.
Ticketing
As soon as we had our ETL constructed and populated, we appeared on the incident frequency in staging and manufacturing relative to the variety of Databricks customers in these environments. We determined that it made sense to mechanically increase a JIRA ticket anytime an exception occurred in staging, whereas in manufacturing, we set the edge at ten distinct classes throughout a launch.
This instantly raised dozens of tickets. The bulk have been ultimately or one other recognized however have been all low sufficient impression that the workforce hadn’t tackled them. In mixture, nonetheless, dozens of small tickets have been vastly regressing our expertise. Round this time, we calculated that 20% of classes noticed a minimum of one error!
With all the info we may pull and enrich, our engineers have been in a position to successfully soar proper right into a repair fairly than wading via completely different companies and logs to get the data they wanted to behave. Because of this, we rapidly burned down a big portion of our points and bought again above our 99.9% error-free aim.

Activity orchestration with Jobs
When executing our pipeline, now we have one pocket book that handles the ETL and one other that compares the state of the delta desk to JIRA and opens any needed points. Working these requires some orchestration, however fortunately, Databricks Jobs makes it simple to deal with this.
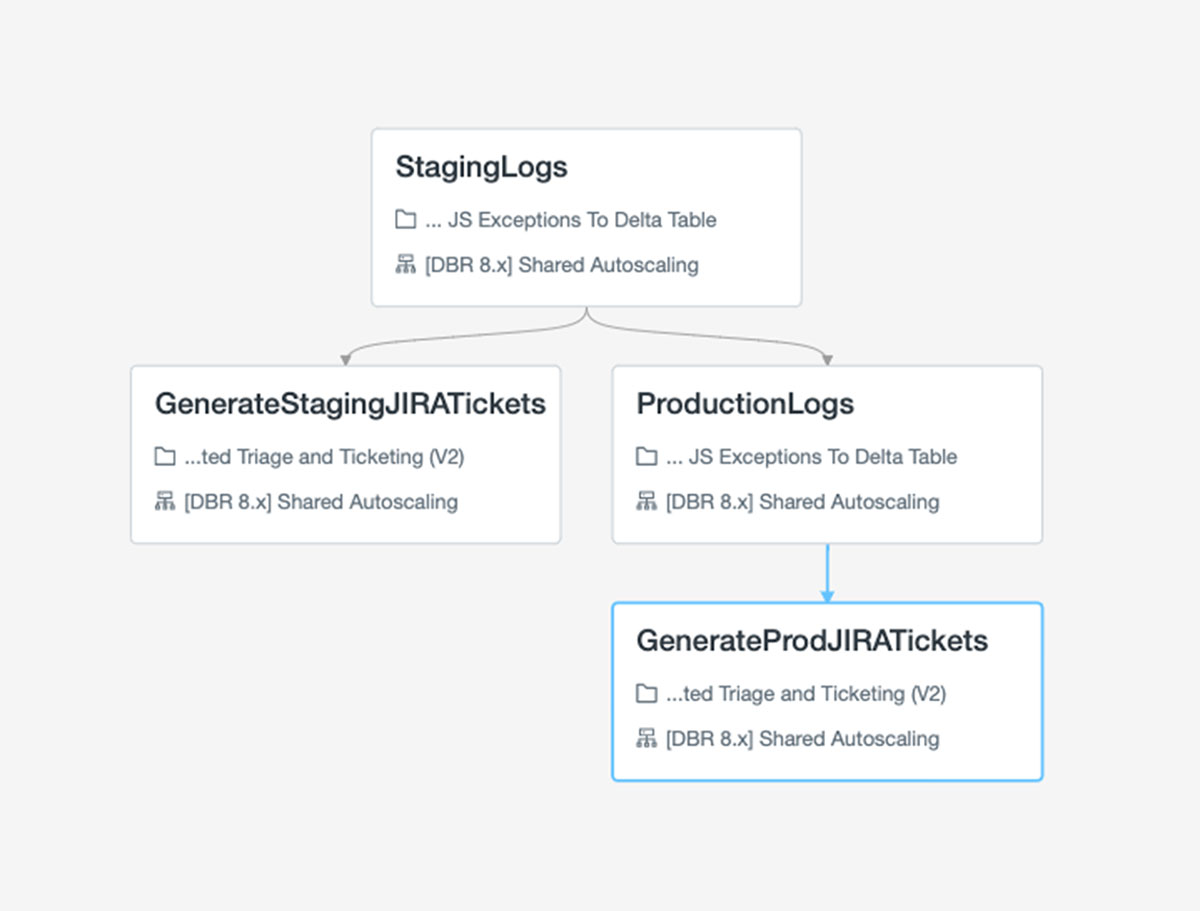
With Jobs, we are able to run these notebooks for staging and manufacturing in sequence. That is very simple to arrange within the net GUI to deal with routing of failures to our workforce’s alert inbox.
Last ideas
General, the merchandise we’ve been constructing at Databricks are extremely highly effective and provides us the potential to construct bespoke monitoring and analytics for something we’re engaged on. We’re utilizing processes like these to observe frontend efficiency, preserve observe of React element utilization, handle dashboards for code migrations and rather more.
Tasks like this one current us with a possibility to make use of our merchandise as a buyer would, to really feel their ache and pleasure and to offer different groups the suggestions they should make Databricks even higher.
If engaged on a platform like this sounds attention-grabbing, we’re hiring! There’s an unbelievable number of frontend work being achieved and being deliberate, and we may use your assist. Come and be a part of us!
[ad_2]


