
[ad_1]
This publish is co-written with Richard Li from SailPoint.
SailPoint Applied sciences is an id safety firm primarily based in Austin, TX. Its software program as a service (SaaS) options help id governance operations in regulated industries resembling healthcare, authorities, and better training. SailPoint distinguishes a number of points of id as particular person id safety companies, together with cloud governance, SaaS administration, entry threat governance, file entry administration, password administration, provisioning, suggestions, and separation of duties, in addition to entry certification, entry insights, entry modeling, and entry requests.
On this publish, we share how SailPoint up to date its platform for large knowledge operations, and solved scaling points by migrating legacy massive knowledge functions to Amazon EMR on Amazon EKS.
The problem with the legacy knowledge setting
SailPoint acquired a SaaS software program platform that processes and analyzes id, useful resource, and utilization knowledge from a number of cloud suppliers, and gives entry insights, utilization evaluation, and entry threat evaluation. The unique design standards of the platform was targeted on serving small to medium-sized corporations. To rapidly course of these analytics insights, many of those processing workloads had been executed inside many microservices via streaming connections.
After acquisition, we set a purpose to increase the platform’s functionality to deal with prospects with giant cloud footprints over a number of cloud suppliers, someday over lots of and even 1000’s of accounts producing great amount of cloud occasion knowledge.
The legacy structure has a simplistic method for knowledge processing, as proven within the following diagram. We had been processing the overwhelming majority of occasion knowledge in-service and instantly ingested into Amazon Relational Database Service (Amazon RDS), which we then merged with a graph database to kind the ultimate view..

We would have liked to transform this right into a scalable course of that would deal with prospects of any dimension. To deal with this problem, we needed to rapidly introduce a giant knowledge processing engine within the platform.
How migrating to Amazon EMR on EKS helped resolve this problem
When evaluating the platform for our massive knowledge operations, a number of components made Amazon EMR on EKS a best choice.
The quantity of occasion knowledge we obtain at any given time is mostly unpredictable. To remain cost-effective and environment friendly, we want a platform that’s able to scaling up routinely when the workload will increase to scale back wait time, and might scale down when the capability is now not wanted to save lots of value. As a result of our current utility workloads are already working on an Amazon Elastic Kubernetes Service (Amazon EKS) cluster with the cluster autoscaler enabled, working Amazon EMR on EKS on high of our current EKS cluster suits this want.
Amazon EMR on EKS can safely coexist on an EKS cluster that’s already internet hosting different workloads, be contained inside a specified namespace, and have managed entry via use of Kubernetes role-based entry management and AWS Id and Entry Administration (IAM) roles for service accounts. Due to this fact, we didn’t must construct new infrastructures only for Amazon EMR. We merely linked up Amazon EMR on EKS with our current EKS cluster working our utility workloads. This decreased the quantity of DevOps help wanted, and considerably sped up our implementation and deployment timeline.
In contrast to Amazon EMR on Amazon Elastic Compute Cloud (Amazon EC2), as a result of our EKS cluster spans over a number of Availability Zones, we will management Spark pods placements utilizing Kubernetes’s pod scheduling and placement technique to realize greater fault tolerance.
With the power to create and use customized photographs in Amazon EMR on EKS, we might additionally make the most of our current container-based utility construct and deployment pipeline for our Amazon EMR on EKS workload with none modifications. This additionally gave us further profit in decreasing job startup time as a result of we package deal all job scripts in addition to all dependencies with the picture, with out having to fetch them at runtime.
We additionally make the most of AWS Step Capabilities as our core workflow engine. The native integration of Amazon EMR on EKS with Step Capabilities is one other bonus the place we didn’t must construct customized code for job dispatch. As a substitute, we might make the most of the Step Capabilities native integration to seamlessly combine Amazon EMR jobs with our current workflow, with little or no effort.
In merely 5 months, we had been capable of go from design, to proof of idea, to rolling out part 1 of the occasion analytics processing. This vastly improved our occasion analytics processing functionality by extending horizontal scalability, which gave us the power to take prospects with considerably bigger cloud footprints than the legacy platform was designed for.
Throughout the growth and rollout of the platform, we additionally discovered that the Spark Historical past Server supplied by Amazon EMR on EKS was very helpful by way of serving to us establish efficiency points and tune the efficiency of our jobs.
As of this writing, the part 1 rollout, which incorporates the occasion processing element of the core analytics processing, is full. We’re now increasing the platform emigrate further elements onto Amazon EMR on EKS. The next diagram depicts our future structure with Amazon EMR on EKS when all phases are full.
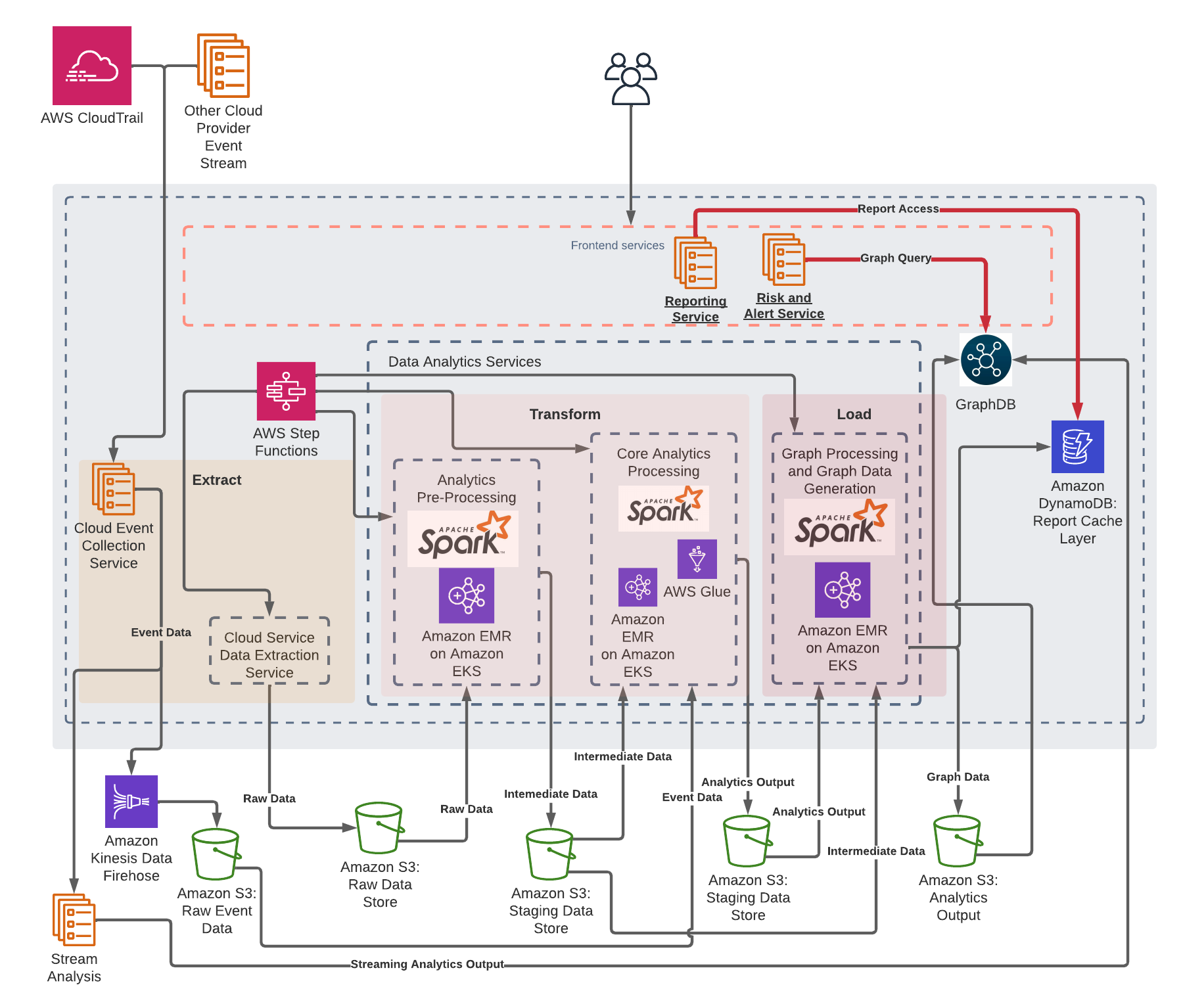
As well as, to enhance performances and cut back prices, we’re presently testing the Spark dynamic useful resource allocation help of Amazon EMR on EKS. This may routinely scale up and down the job executors primarily based on load, and due to this fact enhance efficiency when wanted and cut back value when the workload is low. Moreover, we’re investigating the chance to scale back the general value and enhance efficiency by using the pod template function that might enable us to seamlessly transition our Amazon EMR job workload to AWS Graviton primarily based situations.
Conclusion
With Amazon EMR on EKS, we will now onboard new prospects and course of huge quantities of information in a cheap method, which we couldn’t do with our legacy setting. We plan to increase our Amazon EMR on EKS footprint to deal with all our rework and cargo knowledge analytics processes.
Concerning the Authors
 Richard Li is a senior workers software program engineer on the SailPoint Applied sciences Cloud Entry Administration staff.
Richard Li is a senior workers software program engineer on the SailPoint Applied sciences Cloud Entry Administration staff.
 Janak Agarwal is a product supervisor for Amazon EMR on Amazon EKS at AWS.
Janak Agarwal is a product supervisor for Amazon EMR on Amazon EKS at AWS.
 Kiran Guduguntla is a WW Go-to-Market Specialist for Amazon EMR at AWS. He works with AWS prospects throughout the globe to strategize, construct, develop, and deploy fashionable knowledge analytics options.
Kiran Guduguntla is a WW Go-to-Market Specialist for Amazon EMR at AWS. He works with AWS prospects throughout the globe to strategize, construct, develop, and deploy fashionable knowledge analytics options.
[ad_2]


