
[ad_1]
Tarballs are used industry-wide for packaging and distributing information, and that is no completely different at Databricks. Daily we launch thousands and thousands of VMs throughout a number of cloud suppliers. One of many first steps on each considered one of these VMs is extracting a reasonably sizable tar.lz4 file containing a selected Apache Spark™ runtime. As a part of an effort to assist deliver down bootstrap occasions, we needed to see what might be accomplished to assist pace up the method of extracting this huge tarball.
Current strategies
Proper now, the commonest methodology for extracting tarballs is to invoke some command (e.g. curl, wget, and even their browser) to obtain the uncooked tarball regionally, after which use tar to extract the contents to their last location on disk. There are two common strategies that exist proper now to enhance upon this.
Piping the obtain on to tar
Tar makes use of a sequential file format, which signifies that extraction all the time begins at first of the file and makes its method in direction of the tip. A aspect impact of that is that you simply don’t want all the file current to start extraction. Certainly tar can absorb “-“ because the enter file and it’ll learn from commonplace enter. Couple this with a downloader dumping to plain output (wget -O -) and you’ll successfully begin untarring the file in parallel as the remainder remains to be being downloaded. If each the obtain section and the extraction section take roughly the identical time, this may theoretically halve the full time wanted.
Parallel obtain
Single stream downloaders typically don’t maximize the total bandwidth of a machine on account of bottlenecks within the I/O path (e.g., bandwidth caps set per obtain stream from the obtain supply). Current instruments like aria2c assist mitigate this by downloading with parallel streams from a number of sources to the identical file on disk. This may supply vital speedups, each by using a number of obtain streams and by writing them in parallel to disk.
What fastar does completely different
Parallel downloads + piping
The primary purpose of fastar was to mix the advantages of piping downloads on to tar with the elevated pace of parallel obtain streams. Sadly aria2c is designed for writing on to disk. It doesn’t have the mandatory synchronization mechanisms wanted for changing the a number of obtain streams to a single logical stream for traditional output.
Fastar employs a gaggle of employee threads which are all answerable for downloading their very own slices of the general file. Much like different parallel downloaders, it takes benefit of the HTTP RANGE header to ensure every employee solely downloads the chunk it’s answerable for. The principle distinction is that these staff make use of golang channels and a shared io.Author object to synchronize and merge the completely different obtain streams. This enables for a number of staff to be continuously pulling knowledge in parallel whereas the eventual client solely sees a sequential, in-order stream of bytes.
Assuming 4 employee threads (this quantity is person configurable), the high-level logic is as follows:
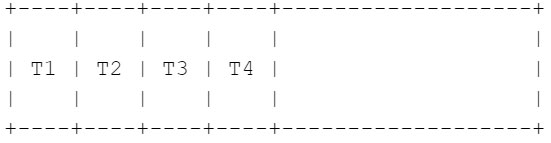
- Kick off threads (T1 – T4), which begin downloading chunks in parallel beginning at first of the file. T1 begins instantly writing to stdout whereas threads T2-T4 save to in-memory buffers till it’s their flip.
- As soon as T1 is completed writing its present chunk to stdout, it indicators T2 that it’s their flip, and begins downloading the following chunk it’s answerable for (proper after T4’s present chunk). T2 begins writing the info they saved of their buffer to stdout whereas the remainder of the threads proceed with their downloads. This course of continues for the entire file.
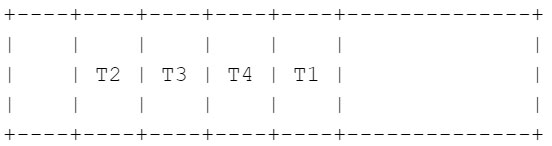
Multithreaded tar extraction
The opposite massive space for enchancment was precise extraction of information to disk by tar itself. As alluded to earlier, one of many causes aria2c is such a quick file downloader is that it writes to disk with a number of streams. Retaining a excessive queue depth when writing ensures that the disk all the time has work to do and isn’t sitting idle ready for the following command. It additionally permits the disk to continuously rearrange write operations to maximise throughput. That is particularly essential when, for instance, untarring many small information. The in-built tar command is single threaded, extracting all information from the archive in a single sizzling loop.
To get round this, fastar additionally makes use of a number of threads for writing particular person extracted information to disk. For every file within the stream, fastar will copy the file knowledge to a buffer, which is then handed to a thread to write down to disk within the background. Some file varieties should be dealt with in a different way right here for correctness. Folders are written synchronously to make sure they exist earlier than any subfiles are written to disk. One other particular case right here is tough hyperlinks. Since they require the dependent file to exist not like symlinks, we have to take care to synchronize file creation round them.
High quality of life options
Fastar additionally features a few options to enhance ease of use:
- S3 hosted obtain help. Fastar additionally helps downloading from S3 buckets utilizing the s3://bucket/key format
- Compression help. Fastar internally handles decompression of gzip and lz4 compressed tarballs. It could possibly even routinely infer which compression schema is utilized by sniffing the primary few bytes for a magic quantity.
Efficiency numbers
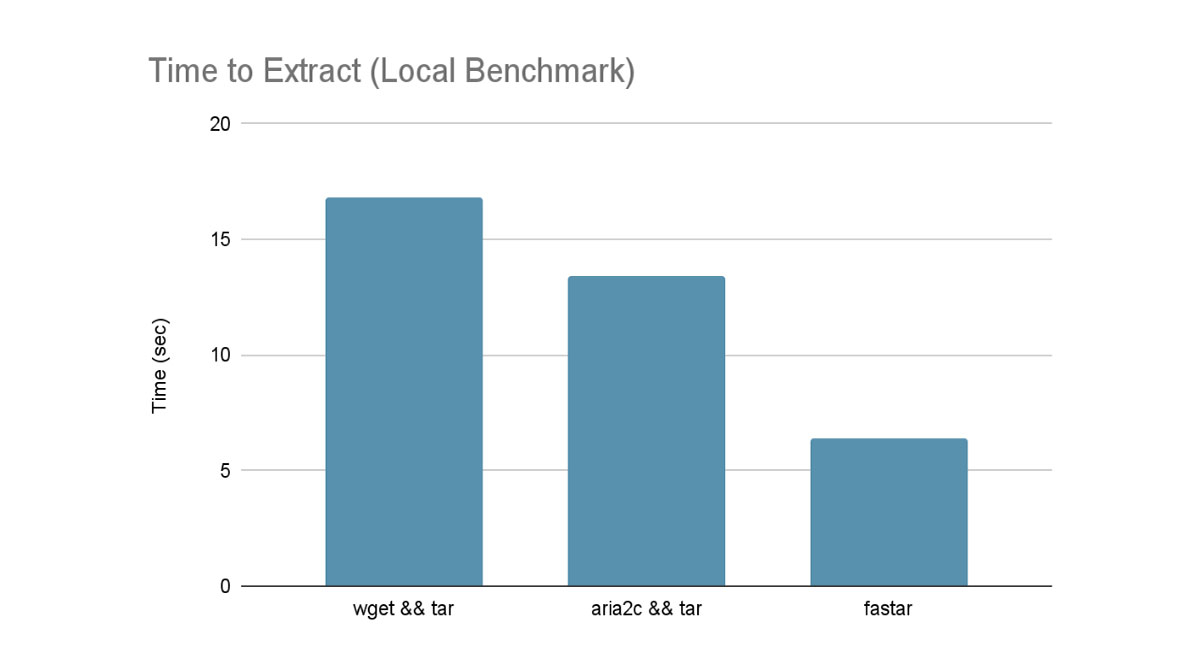
To check regionally, we used an lz4 compressed tarball of a container filesystem (2.6GB compressed, 4.3GB uncompressed). This was hosted on a neighborhood HTTP server serving from an in-memory file system. The tarball was then downloaded and extracted to the identical in-memory file system. This could symbolize a theoretical finest case state of affairs as we aren’t IO sure with the reminiscence backed file system.
For manufacturing affect, the next reveals the pace distinction when extracting one of many largest pictures we help on a dwell cluster (7.6GB compressed, 16.1GB uncompressed). Pre-fastar, we used aria2c on Azure and boto3 on AWS to obtain the picture earlier than extracting it with tar.
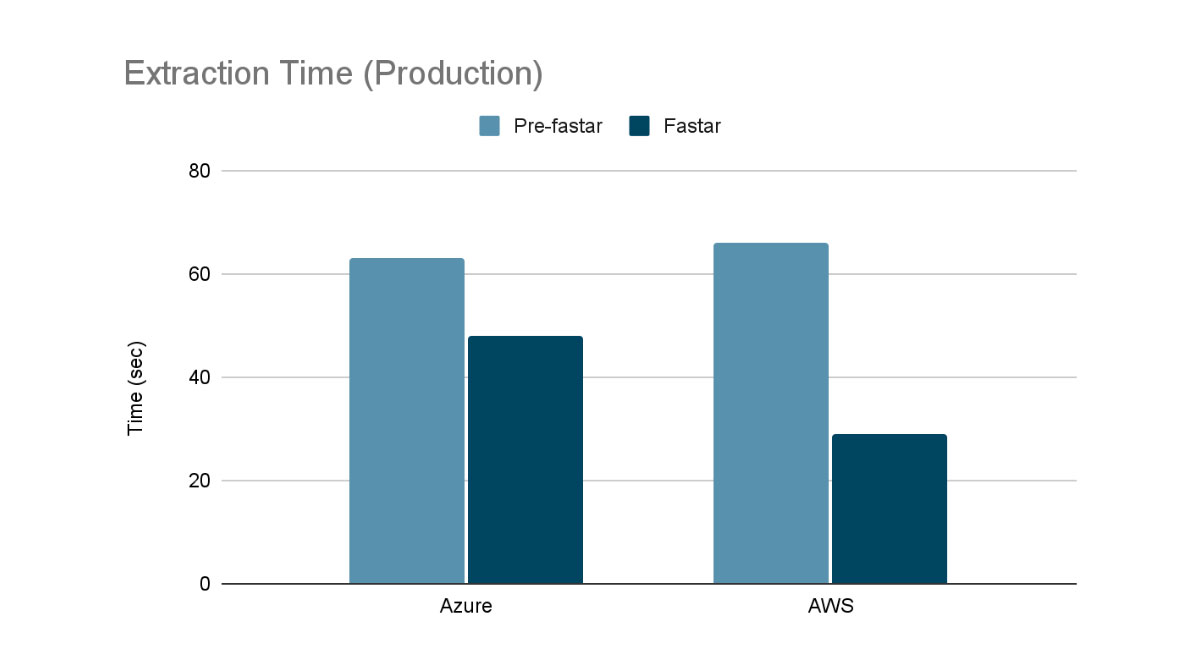
From the assessments above, fastar can supply vital pace enhancements, each in artificial and real-world benchmarks. In artificial workloads we obtain an almost 3x enchancment over naively calling wget && tar and double the efficiency in comparison with utilizing the already quick aria2c && tar. Lastly in manufacturing workloads we see a 1.3x enchancment in Azure Databricks and over a 2x enchancment in Databricks on AWS.
Excited about engaged on issues like this? Take into account making use of to Databricks!
Additionally tell us when you would discover this software helpful and we are able to look into open sourcing it!
[ad_2]


