[ad_1]
At the moment’s companies face an unprecedented progress within the quantity of information. A rising portion of the information is generated in actual time by IoT gadgets, web sites, enterprise functions, and varied different sources. Companies have to course of and analyze this knowledge as quickly because it arrives to make enterprise selections in actual time. Amazon Managed Streaming for Apache Kafka (Amazon MSK) is a completely managed service that permits constructing and working stream processing functions that use Apache Kafka to gather and course of knowledge in actual time.
Stream processing functions utilizing Apache Kafka don’t talk with one another instantly; they convey by way of sending and receiving messages over Kafka subjects. For stream processing functions to speak effectively and confidently, a message payload construction have to be outlined by way of attributes and knowledge sorts. This construction describes the schema functions use when sending and receiving messages. Nonetheless, with a lot of producer and shopper functions, even a small change in schema (eradicating a discipline, including a brand new discipline, or change in knowledge sort) could trigger points for downstream functions which are tough to debug and repair.
Historically, groups have relied on change administration processes (reminiscent of approvals and upkeep home windows) or different casual mechanisms (documentation, emails, collaboration instruments, and so forth) to tell each other of information schema adjustments. Nonetheless, these mechanisms don’t scale and are vulnerable to errors. The AWS Glue Schema Registry lets you centrally publish, uncover, management, validate, and evolve schemas for stream processing functions. With the AWS Glue Schema Registry, you possibly can handle and implement schemas on knowledge streaming functions utilizing Apache Kafka, Amazon MSK, Amazon Kinesis Information Streams, Amazon Kinesis Information Analytics for Apache Flink, and AWS Lambda.
This put up demonstrates how Apache Kafka stream processing functions validate messages utilizing an Apache Avro schema saved within the AWS Glue Schema registry residing in a central AWS account. We use the AWS Glue Schema Registry SerDe library and Avro SpecificRecord to validate messages in stream processing functions whereas sending and receiving messages from a Kafka matter on an Amazon MSK cluster. Though we use an Avro schema for this put up, the identical method and idea applies to JSON schemas as properly.
Use case
Let’s assume a fictitious rideshare firm that gives unicorn rides. To attract actionable insights, they should course of a stream of unicorn trip request messages. They anticipate rides to be extremely popular and need to make sure that their answer can scale. They’re additionally constructing a central knowledge lake the place all their streaming and operation knowledge is saved for evaluation. They’re buyer obsessed, so that they anticipate so as to add new enjoyable options to future rides, like selecting the hair colour of your unicorn, and might want to replicate these attributes within the trip request messages. To keep away from points in downstream functions as a result of future schema adjustments, they want a mechanism to validate messages with a schema hosted in a central schema registry. Having schemas in a central schema registry makes it simpler for the applying groups to publish, validate, evolve, and keep schemas in a single place.
Answer overview
The corporate makes use of Amazon MSK to seize and distribute the unicorn trip request messages at scale. They outline an Avro schema for unicorn trip requests as a result of it supplies wealthy knowledge buildings, helps direct mapping to JSON, in addition to a compact, quick, and binary knowledge format. As a result of the schema was agreed prematurely, they determined to make use of Avro SpecificRecord.SpecificRecord is an interface from the Avro library that enables using an Avro file as a POJO. That is accomplished by producing a Java class (or courses) from the schema, by utilizing avro-maven-plugin. They use AWS Identification and Entry Administration (IAM) cross-account roles to permit producer and shopper functions from the opposite AWS account to securely and securely entry schemas within the central Schema Registry account.
The AWS Glue Schema Registry is in Account B, whereas the MSK cluster and Kafka producer and shopper functions are in Account A. We use the next two IAM roles to allow cross-account entry to the AWS Glue Schema Registry. Apache Kafka shoppers in Account A assume a task in Account B utilizing an identity-based coverage as a result of the AWS Glue Schema Registry doesn’t assist resource-based insurance policies.
- Account A IAM function – Permits producer and shopper functions to imagine an IAM function in Account B.
- Account B IAM function – Trusts all IAM principals from Account A and permits them to carry out learn actions on the AWS Glue Schema Registry in Account B. In an actual use case situation, IAM principals that may assume cross-account roles must be scoped extra particularly.
The next structure diagram illustrates the answer:

The answer works as follows:
- A Kafka producer working in Account A assumes the cross-account Schema Registry IAM function in Account B by calling the AWS Safety Token Service (AWS STS)
assumeRoleAPI. - The Kafka producer retrieves the unicorn trip request Avro schema model ID from the AWS Glue Schema Registry for the schema that’s embedded within the unicorn trip request POJO. Fetching the schema model ID is internally managed by the AWS Glue Schema Registry SerDe’s serializer. The serializer must be configured as a part of the Kafka producer configuration.
- If the schema exists within the AWS Glue Schema Registry, the serializer decorates the information file with the schema model ID after which serializes it earlier than delivering it to the Kafka matter on the MSK cluster.
- The Kafka shopper working in Account A assumes the cross-account Schema Registry IAM function in Account B by calling the AWS STS
assumeRoleAPI. - The Kafka shopper begins polling the Kafka matter on the MSK cluster for knowledge data.
- The Kafka shopper retrieves the unicorn trip request Avro schema from the AWS Glue Schema Registry, matching the schema model ID that’s encoded within the unicorn trip request knowledge file. Fetching the schema is internally managed by the AWS Glue Schema Registry SerDe’s deserializer. The deserializer must be configured as a part of the Kafka shopper configuration. If the schema exists within the AWS Glue Schema Registry, the deserializer deserializes the information file into the unicorn trip request POJO for the buyer to course of it.
The AWS Glue Schema Registry SerDe library additionally helps optionally available compression configuration to save lots of on knowledge transfers. For extra details about the Schema Registry, see How the Schema Registry works.
Unicorn trip request Avro schema
The next schema (UnicornRideRequest.avsc) defines a file representing a unicorn trip request, which comprises trip request attributes together with the client attributes and system-recommended unicorn attributes:
Stipulations
To make use of this answer, you will need to have two AWS accounts:
- Account A – For the MSK cluster, Kafka producer and shopper Amazon Elastic Compute Cloud (Amazon EC2) cases, and AWS Cloud9 atmosphere
- Account B – For the Schema Registry and schema
For this answer, we use Area us-east-1, however you possibly can change this as per your necessities.
Subsequent, we create the assets in every account utilizing AWS CloudFormation templates.
Create assets in Account B
We create the next assets in Account B:
- A schema registry
- An Avro schema
- An IAM function with the
AWSGlueSchemaRegistryReadonlyAccessmanaged coverage and an occasion profile, which permits all Account A IAM principals to imagine it - The
UnicornRideRequest.avscAvro schema proven earlier, which is used as a schema definition within the CloudFormation template
Ensure you have the suitable permissions to create these assets.
- Log in to Account B.
- Launch the next CloudFormation stack.
- For Stack identify, enter
SchemaRegistryStack. - For Schema Registry identify, enter
unicorn-ride-request-registry. - For Avro Schema identify, enter
unicorn-ride-request-schema-avro. - For the Kafka consumer’s AWS account ID, enter your Account A ID.
- For ExternalId, enter a singular random ID (for instance,
demo10A), which must be supplied by the Kafka shoppers in Account Some time assuming the IAM function on this account.
For extra details about cross-account safety, see The confused deputy downside.
- When the stack is full, on the Outputs tab of the stack, copy the worth for
CrossAccountGlueSchemaRegistryRoleArn.
The Kafka producer and shopper functions created in Account A assume this function to entry the Schema Registry and schema in Account B.
- To confirm the assets had been created, on the AWS Glue console, select Schema registries within the navigation bar, and find
unicorn-ride-request-registry.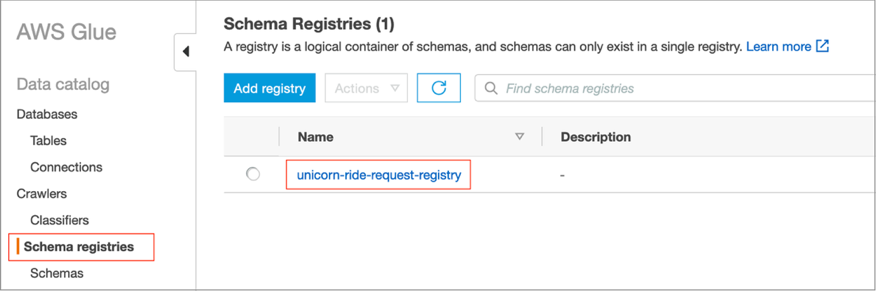
- Select the registry
unicorn-ride-request-registryand confirm that it comprisesunicorn-ride-request-schema-avrowithin the Schemas part. - Select the schema to see its content material.

The IAM function created by the SchemaRegistryStack stack permits all Account A IAM principals to imagine it and carry out learn actions on the AWS Glue Schema Registry. Let’s have a look at the belief relationships of the IAM function.
- On the
SchemaRegistryStackstack Outputs tab, copy the worth forCrossAccountGlueSchemaRegistryRoleName. - On the IAM console, seek for this function.
- Select Belief relationships and have a look at its trusted entities to verify that Account A is listed.
- Within the Circumstances part, verify that
sts:ExternalIdhas the identical distinctive random ID supplied throughout stack creation.
Create assets in Account A
We create the next assets in Account A:
- A VPC
- EC2 cases for the Kafka producer and shopper
- An AWS Cloud9 atmosphere
- An MSK cluster
As a prerequisite, create an EC2 keypair and obtain it in your machine to have the ability to SSH into EC2 cases. Additionally create an MSK cluster configuration with default values. You might want to have permissions to create the CloudFormation stack, EC2 cases, AWS Cloud9 atmosphere, MSK cluster, MSK cluster configuration, and IAM function.
- Log in to Account A.
- Launch the next CloudFormation stack to launch the VPC, EC2 cases, and AWS Cloud9 atmosphere.
- For Stack identify, enter
MSKClientStack. - Present the VPC and subnet CIDR ranges.
- For EC2 Keypair, select an current EC2 keypair.
- For the newest EC2 AMI ID, choose the default choice.
- For the cross-account IAM function ARN, use the worth for
CrossAccountGlueSchemaRegistryRoleArn(out there on the Outputs tab ofSchemaRegistryStack). - Look ahead to the stack to create efficiently.
- Launch the next CloudFormation stack to create the MSK cluster.
- For Stack identify, enter
MSKClusterStack. - Use Amazon MSK model 2.7.1.
- For the MSK cluster configuration ARN, enter the MSK cluster configuration ARN. One that you simply created as a part of the prerequisite.
- For the MSK cluster configuration revision quantity, enter 1 or change it based on your model.
- For the consumer CloudFormation stack identify, enter
MSKClientStack(the stack identify that you simply created previous to this stack).
Configure the Kafka producer
To configure the Kafka producer accessing the Schema Registry within the central AWS account, full the next steps:
- Log in to Account A.
- On the AWS Cloud9 console, select the
Cloud9EC2Bastionatmosphere created by theMSKClientStackstack. - On the File menu, select Add Native Information.
- Add the EC2 keypair file that you simply used earlier whereas creating the stack.

- Open a brand new terminal and alter the EC2 keypair permissions:
- SSH into the
KafkaProducerInstanceEC2 occasion and set the Area as per your requirement: - Set the atmosphere variable
MSK_CLUSTER_ARNpointing to the MSK cluster’s ARN:
Change the .ClusterName worth within the code for those who used a special identify for the MSK cluster CloudFormation stack. The cluster identify is identical because the stack identify.
- Set the atmosphere variable
BOOTSTRAP_BROKERSpointing to the bootstrap brokers: - Confirm the atmosphere variables:
- Create a Kafka matter known as
unicorn-ride-request-topicin your MSK cluster, which is utilized by the Kafka producer and shopper functions later:
The MSKClientStack stack copied the Kafka producer consumer JAR file known as kafka-cross-account-gsr-producer.jar to the KafkaProducerInstance occasion. It comprises the Kafka producer consumer that sends messages to the Kafka matter unicorn-ride-request-topic on the MSK cluster and accesses the unicorn-ride-request-schema-avro Avro schema from the unicorn-ride-request-registry schema registry in Account B. The Kafka producer code, which we cowl later on this put up, is accessible on GitHub.
- Run the next instructions and confirm
kafka-cross-account-gsr-producer.jarexists: - Run the next command to run the Kafka producer within the
KafkaProducerInstanceterminal:
The code has the next parameters:
- -bs –
$BOOTSTRAP_BROKERS(the MSK cluster bootstrap brokers) - -rn – The
CrossAccountGlueSchemaRegistryRoleArnworth from theSchemaRegistryStackstack outputs in Account B - -topic – the Kafka matter
unicorn-ride-request-topic - -reg –
us-east-1(change it based on your Area, it’s used for the AWS STS endpoint and Schema Registry) - -nm:
500(the variety of messages the producer software sends to the Kafka matter) - -externalId – The identical exterior ID (for instance,
demo10A) that you simply used whereas creating the CloudFormation stack in Account B
The next screenshot reveals the Kafka producer logs exhibiting Schema Model Id obtained..., which implies it has retrieved the Avro schema unicorn-ride-request-schema-avro from Account B and messages had been despatched to the Kafka matter on the MSK cluster in Account A.

Kafka producer code
The whole Kafka producer implementation is accessible on GitHub. On this part, we break down the code.
getProducerConfig()initializes the producer properties, as proven within the following code:- VALUE_SERIALIZER_CLASS_CONFIG – The
GlueSchemaRegistryKafkaSerializer.class.getName()AWS serializer implementation that serializes knowledge data (the implementation is accessible on GitHub) - REGISTRY_NAME – The Schema Registry from Account B
- SCHEMA_NAME – The schema identify from Account B
- AVRO_RECORD_TYPE –
AvroRecordType.SPECIFIC_RECORD
- VALUE_SERIALIZER_CLASS_CONFIG – The
startProducer()assumes the function in Account B to have the ability to join with the Schema Registry in Account B and sends messages to the Kafka matter on the MSK cluster:
assumeGlueSchemaRegistryRole()as proven within the following code makes use of AWS STS to imagine the cross-account Schema Registry IAM function in Account B. (For extra info, see Non permanent safety credentials in IAM.) The response fromstsClient.assumeRole(roleRequest)comprises the momentary credentials, which embraceaccessKeyId,secretAccessKey, and asessionToken. It then units the momentary credentials within the system properties. The AWS SDK for Java makes use of these credentials whereas accessing the Schema Registry (by way of the Schema Registry serializer). For extra info, see Utilizing Credentials.createUnicornRideRequest()makes use of the Avro schema (unicorn trip request schema) generated courses to create aSpecificRecord. For this put up, the unicorn trip request attributes values are hard-coded on this technique. See the next code:
Configure the Kafka shopper
The MSKClientStack stack created the KafkaConsumerInstance occasion for the Kafka shopper software. You possibly can view all of the cases created by the stack on the Amazon EC2 console.
To configure the Kafka shopper accessing the Schema Registry within the central AWS account, full the next steps:
- Open a brand new terminal within the
Cloud9EC2BastionAWS Cloud9 atmosphere.
- SSH into the
KafkaConsumerInstanceEC2 occasion and set the Area as per your requirement: - Set the atmosphere variable
MSK_CLUSTER_ARNpointing to the MSK cluster’s ARN:
Change the .ClusterName worth for those who used a special identify for the MSK cluster CloudFormation stack. The cluster identify is identical because the stack identify.
- Set the atmosphere variable
BOOTSTRAP_BROKERSpointing to the bootstrap brokers: - Confirm the atmosphere variables:
The MSKClientStack stack copied the Kafka shopper consumer JAR file known as kafka-cross-account-gsr-consumer.jar to the KafkaConsumerInstance occasion. It comprises the Kafka shopper consumer that reads messages from the Kafka matter unicorn-ride-request-topic on the MSK cluster and accesses the unicorn-ride-request-schema-avro Avro schema from the unicorn-ride-request-registry registry in Account B. The Kafka shopper code, which we cowl later on this put up, is accessible on GitHub.
- Run the next instructions and confirm
kafka-cross-account-gsr-consumer.jarexists: - Run the next command to run the Kafka shopper within the
KafkaConsumerInstanceterminal:
The code has the next parameters:
- -bs –
$BOOTSTRAP_BROKERS(the MSK cluster bootstrap brokers) - -rn – The
CrossAccountGlueSchemaRegistryRoleArnworth from theSchemaRegistryStackstack outputs in Account B - -topic – The Kafka matter
unicorn-ride-request-topic - -reg –
us-east-1(change it based on your Area, it’s used for the AWS STS endpoint and Schema Registry) - -externalId – The identical exterior ID (for instance,
demo10A) that you simply used whereas creating the CloudFormation stack in Account B
The next screenshot reveals the Kafka shopper logs efficiently studying messages from the Kafka matter on the MSK cluster in Account A and accessing the Avro schema unicorn-ride-request-schema-avro from the unicorn-ride-request-registry schema registry in Account B.

When you see the same logs, it means each the Kafka shopper functions have been in a position to join efficiently with the centralized Schema Registry in Account B and are in a position to validate messages whereas sending and consuming messages from the MSK cluster in Account A.
Kafka shopper code
The whole Kafka shopper implementation is accessible on GitHub. On this part, we break down the code.
getConsumerConfig()initializes shopper properties, as proven within the following code:- VALUE_DESERIALIZER_CLASS_CONFIG – The
GlueSchemaRegistryKafkaDeserializer.class.getName()AWS deserializer implementation that deserializes theSpecificRecordas per the encoded schema ID from the Schema Registry (the implementation is accessible on GitHub). - AVRO_RECORD_TYPE –
AvroRecordType.SPECIFIC_RECORD
- VALUE_DESERIALIZER_CLASS_CONFIG – The
startConsumer()assumes the function in Account B to have the ability to join with the Schema Registry in Account B and reads messages from the Kafka matter on the MSK cluster:
assumeGlueSchemaRegistryRole()as proven within the following code makes use of AWS STS to imagine the cross-account Schema Registry IAM function in Account B. The response fromstsClient.assumeRole(roleRequest)comprises the momentary credentials, which embraceaccessKeyId,secretAccessKey, and asessionToken. It then units the momentary credentials within the system properties. The SDK for Java makes use of these credentials whereas accessing the Schema Registry (by way of the Schema Registry serializer). For extra info, see Utilizing Credentials.
Compile and generate Avro schema courses
Like another a part of constructing and deploying your software, schema compilation and the method of producing Avro schema courses must be included in your CI/CD pipeline. There are a number of methods to generate Avro schema courses; we use avro-maven-plugin for this put up. The CI/CD course of may also use avro-tools to compile Avro schema to generate courses. The next code is an instance of how you should use avro-tools:
Implementation overview
To recap, we begin with defining and registering an Avro schema for the unicorn trip request message within the AWS Glue Schema Registry in Account B, the central knowledge lake account. In Account A, we create an MSK cluster and Kafka producer and shopper EC2 cases with their respective software code (kafka-cross-account-gsr-consumer.jar and kafka-cross-account-gsr-producer.jar) and deployed in them utilizing the CloudFormation stack.
After we run the producer software in Account A, the serializer (GlueSchemaRegistryKafkaSerializer) from the AWS Glue Schema Registry SerDe library supplied because the configuration will get the unicorn trip request schema (UnicornRideRequest.avsc) from the central Schema Registry residing in Account B to serialize the unicorn trip request message. It makes use of the IAM function (momentary credentials) in Account B and Area, schema registry identify (unicorn-ride-request-registry), and schema identify (unicorn-ride-request-schema-avro) supplied because the configuration to connect with the central Schema Registry. After the message is efficiently serialized, the producer software sends it to the Kafka matter (unicorn-ride-request-topic) on the MSK cluster.
After we run the buyer software in Account A, the deserializer (GlueSchemaRegistryKafkaDeserializer) from the Schema Registry SerDe library supplied because the configuration extracts the encoded schema ID from the message learn from the Kafka matter (unicorn-ride-request-topic) and will get the schema for a similar ID from the central Schema Registry in Account B. It then deserializes the message. It makes use of the IAM function (momentary credentials) in Account B and the Area supplied because the configuration to connect with the central Schema Registry. The buyer software additionally configures Avro’s SPECIFIC_RECORD to tell the deserializer that the message is of a particular sort (unicorn trip request). After the message is efficiently deserialized, the buyer software processes it as per the necessities.
Clear up
The ultimate step is to wash up. To keep away from pointless fees, you need to take away all of the assets created by the CloudFormation stacks used for this put up. The best approach to take action is to delete the stacks. First delete the MSKClusterStack adopted by MSKClientStack from Account A. Then delete the SchemaRegistryStack from Account B.
Conclusion
On this put up, we demonstrated tips on how to use AWS Glue Schema Registry with Amazon MSK and stream processing functions to validate messages utilizing an Avro schema. We created a distributed structure the place the Schema Registry resides in a central AWS account (knowledge lake account) and Kafka producer and shopper functions reside in a separate AWS account. We created an Avro schema within the schema registry within the central account to make it environment friendly for the applying groups to take care of schemas in a single place. As a result of AWS Glue Schema Registry helps identity-based entry insurance policies, we used the cross-account IAM function to permit the Kafka producer and shopper functions working in a separate account to securely entry the schema from the central account to validate messages. As a result of the Avro schema was agreed prematurely, we used Avro SpecificRecord to make sure sort security at compile time and keep away from runtime schema validation points on the consumer facet. The code used for this put up is accessible on GitHub for reference.
To be taught extra concerning the providers and assets on this answer, seek advice from AWS Glue Schema Registry, the Amazon MSK Developer Information, the AWS Glue Schema Registry SerDe library, and IAM tutorial: Delegate entry throughout AWS accounts utilizing IAM roles.
In regards to the Writer
 Vikas Bajaj is a Principal Options Architect at Amazon Internet Service. Vikas works with digital native prospects and advises them on expertise structure and modeling, and choices and options to satisfy strategic enterprise goals. He makes positive designs and options are environment friendly, sustainable, and fit-for-purpose for present and future enterprise wants. Aside from structure and expertise discussions, he enjoys watching and enjoying cricket.
Vikas Bajaj is a Principal Options Architect at Amazon Internet Service. Vikas works with digital native prospects and advises them on expertise structure and modeling, and choices and options to satisfy strategic enterprise goals. He makes positive designs and options are environment friendly, sustainable, and fit-for-purpose for present and future enterprise wants. Aside from structure and expertise discussions, he enjoys watching and enjoying cricket.
[ad_2]


