











ETL orchestration utilizing the Amazon Redshift Information API and AWS Step Features with AWS SDK integration
Extract, rework, and cargo (ETL) serverless orchestration structure functions have gotten fashionable with many shoppers. These functions provides better extensibility and ease, making it simpler to keep up and simplify ETL pipelines. A major good thing about this structure is that we simplify an present ETL pipeline with AWS Step Features and straight name the Amazon Redshift Information API from the state machine. In consequence, the complexity for the ETL pipeline is decreased.
As an information engineer or an utility developer, you could wish to work together with Amazon Redshift to load or question knowledge with a easy API endpoint with out having to handle persistent connections. The Amazon Redshift Information API lets you work together with Amazon Redshift with out having to configure JDBC or ODBC connections. This function lets you orchestrate serverless knowledge processing workflows, design event-driven net functions, and run an ETL pipeline asynchronously to ingest and course of knowledge in Amazon Redshift, with using Step Features to orchestrate the complete ETL or ELT workflow.
This submit explains find out how to use Step Features and the Amazon Redshift Information API to orchestrate the completely different steps in your ETL or ELT workflow and course of knowledge into an Amazon Redshift knowledge warehouse.
AWS Lambda is usually used with Step Features because of its versatile and scalable compute advantages. An ETL workflow has a number of steps, and the complexity could range inside every step. Nevertheless, there may be another strategy with AWS SDK service integrations, a function of Step Features. These integrations permit you to name over 200 AWS companies’ API actions straight out of your state machine. This strategy is perfect for steps with comparatively low complexity in comparison with utilizing Lambda since you now not have to keep up and check operate code. Lambda capabilities have a most timeout of quarter-hour; if you want to look forward to longer-running processes, Step Features normal workflows permits a most runtime of 1 12 months.
You possibly can substitute steps that embrace a single course of with a direct integration between Step Features and AWS SDK service integrations with out utilizing Lambda. For instance, if a step is barely used to name a Lambda operate that runs a SQL assertion in Amazon Redshift, you could take away the Lambda operate with a direct integration to the Amazon Redshift Information API’s SDK API motion. You too can decouple Lambda capabilities with a number of actions into a number of steps. An implementation of that is out there later on this submit.
We created an instance use case within the GitHub repo ETL Orchestration utilizing Amazon Redshift Information API and AWS Step Features that gives an AWS CloudFormation template for setup, SQL scripts, and a state machine definition. The state machine straight reads SQL scripts saved in your Amazon Easy Storage Service (Amazon S3) bucket, runs them in your Amazon Redshift cluster, and performs an ETL workflow. We don’t use Lambda on this use case.
Answer overview
On this situation, we simplify an present ETL pipeline that makes use of Lambda to name the Information API. AWS SDK service integrations with Step Features permit you to straight name the Information API from the state machine, lowering the complexity in operating the ETL pipeline.
All the workflow performs the next steps:
- Arrange the required database objects and generate a set of pattern knowledge to be processed.
- Run two dimension jobs that carry out SCD1 and SCD2 dimension load, respectively.
- When each jobs have run efficiently, the load job for the actual fact desk runs.
- The state machine performs a validation to make sure the gross sales knowledge was loaded efficiently.

The next structure diagram highlights the end-to-end answer: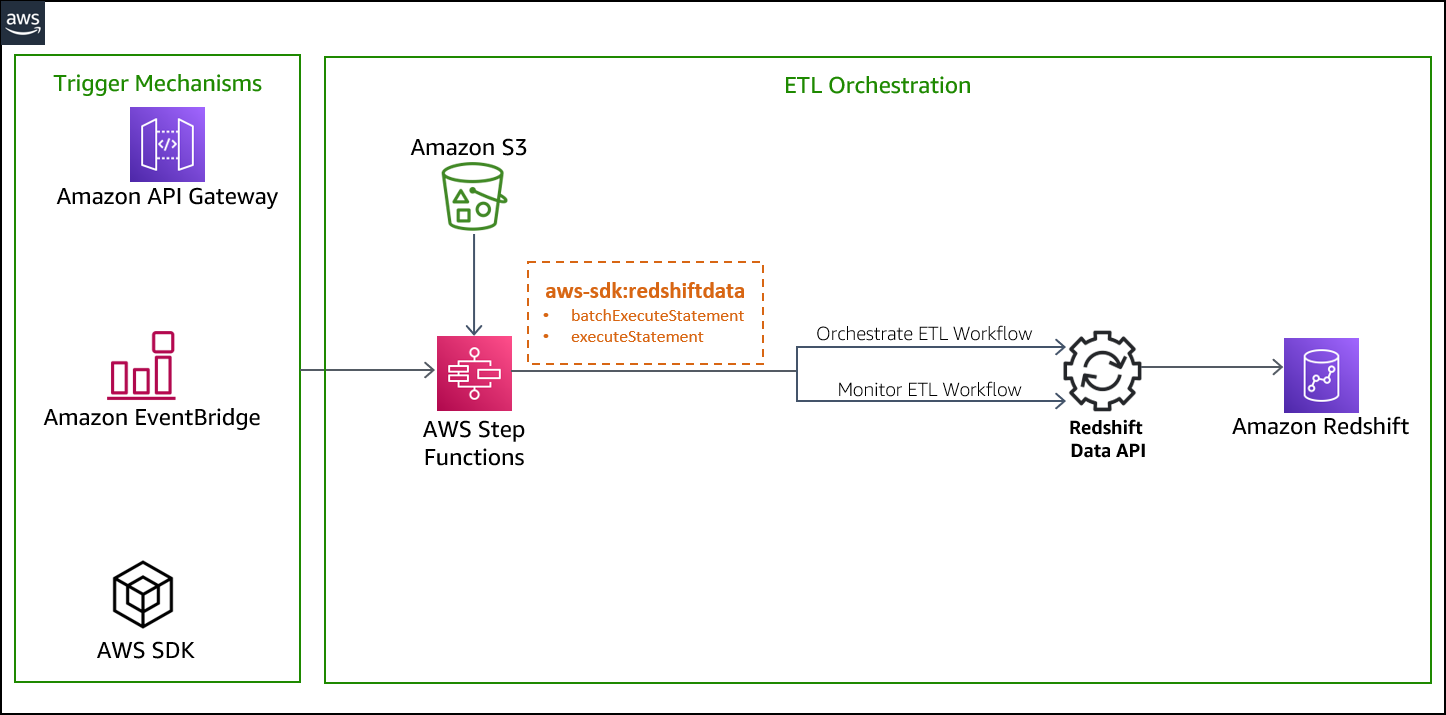
We run the state machine through the Step Features console, however you may run this answer in a number of methods:
You possibly can deploy the answer with the offered CloudFormation template, which creates the next sources:
- Database objects within the Amazon Redshift cluster:
- 4 saved procedures:
- sp_setup_sales_data_pipeline() – Creates the tables and populates them with pattern knowledge
- sp_load_dim_customer_address() – Runs the SCD1 course of on
customer_addressdata - sp_load_dim_item() – Runs the SCD2 course of on
merchandisedata - sp_load_fact_sales (p_run_date date) – Processes gross sales from all shops for a given day
- 5 Amazon Redshift tables:
buyercustomer_addressdate_dimmerchandisestore_sales
- 4 saved procedures:
- The AWS Id and Entry Administration (IAM) position
StateMachineExecutionRolefor Step Features to permit the next permissions:- Federate to the Amazon Redshift cluster by way of
getClusterCredentialspermission avoiding password credentials - Run queries within the Amazon Redshift cluster by way of Information API calls
- Record and retrieve objects from Amazon S3
- Federate to the Amazon Redshift cluster by way of
- The Step Features state machine
RedshiftETLStepFunction, which incorporates the steps used to run the ETL workflow of the pattern gross sales knowledge pipeline
Stipulations
As a prerequisite for deploying the answer, you want to arrange an Amazon Redshift cluster and affiliate it with an IAM position. For extra data, see Authorizing Amazon Redshift to entry different AWS companies in your behalf. When you don’t have a cluster provisioned in your AWS account, seek advice from Getting began with Amazon Redshift for directions to set it up.
When the Amazon Redshift cluster is on the market, carry out the next steps:
- Obtain and save the CloudFormation template to an area folder in your pc.
- Obtain and save the next SQL scripts to an area folder in your pc:
- sp_statements.sql – Accommodates the saved procedures together with DDL and DML operations.
- validate_sql_statement.sql – Accommodates two validation queries you may run.
- Add the SQL scripts to your S3 bucket. The bucket title is the designated S3 bucket specified within the
ETLScriptS3Pathenter parameter. - On the AWS CloudFormation console, select Create stack with new sources and add the template file you downloaded within the earlier step (
etl-orchestration-with-stepfunctions-and-redshift-data-api.yaml). - Enter the required parameters and select Subsequent.

- Select Subsequent till you get to the Assessment web page and choose the acknowledgement examine field.
- Select Create stack.

- Wait till the stack deploys efficiently.
When the stack is full, you may view the outputs, as proven within the following screenshot:
Run the ETL orchestration
After you deploy the CloudFormation template, navigate to the stack element web page. On the Sources tab, select the hyperlink for RedshiftETLStepFunction to be redirected to the Step Features console.
The RedshiftETLStepFunction state machine runs routinely, as outlined within the following workflow:
- read_sp_statement and run_sp_deploy_redshift – Performs the next actions:
- Retrieves the
sp_statements.sqlfrom Amazon S3 to get the saved process. - Passes the saved process to the
batch-execute-statementAPI to run within the Amazon Redshift cluster. - Sends again the identifier of the SQL assertion to the state machine.
- Retrieves the
- wait_on_sp_deploy_redshift – Waits for a minimum of 5 seconds.
- run_sp_deploy_redshift_status_check – Invokes the Information API’s
describeStatementto get the standing of the API name. - is_run_sp_deploy_complete – Routes the subsequent step of the ETL workflow relying on its standing:
- FINISHED – Saved procedures are created in your Amazon Redshift cluster.
- FAILED – Go to the
sales_data_pipeline_failurestep and fail the ETL workflow. - All different standing – Return to the
wait_on_sp_deploy_redshiftstep to attend for the SQL statements to complete.
- setup_sales_data_pipeline – Performs the next steps:
- Initiates the
setupsaved process that was beforehand created within the Amazon Redshift cluster. - Sends again the identifier of the SQL assertion to the state machine.
- Initiates the
- wait_on_setup_sales_data_pipeline – Waits for a minimum of 5 seconds.
- setup_sales_data_pipeline_status_check – Invokes the Information API’s
describeStatementto get the standing of the API name. - is_setup_sales_data_pipeline_complete – Routes the subsequent step of the ETL workflow relying on its standing:
- FINISHED – Created two dimension tables (
customer_addressandmerchandise) and one truth desk (gross sales). - FAILED – Go to the
sales_data_pipeline_failurestep and fail the ETL workflow. - All different standing – Return to the
wait_on_setup_sales_data_pipelinestep to attend for the SQL statements to complete.
- FINISHED – Created two dimension tables (
- run_sales_data_pipeline –
LoadItemTableandLoadCustomerAddressTableare two parallel workflows that Step Features runs on the similar time. The workflows run the saved procedures that have been beforehand created. The saved process hundreds the information into themerchandiseandcustomer_addresstables. All different steps within the parallel classes observe the identical idea as described beforehand. When each parallel workflows are full,run_load_fact_salesruns. - run_load_fact_sales – Inserts knowledge into the
store_salesdesk that was created within the preliminary saved process. - Validation – When all of the ETL steps are full, the state machine reads a second SQL file from Amazon S3 (
validate_sql_statement.sql) and runs the 2 SQL statements utilizing thebatch_execute_statementmethodology.
The implementation of the ETL workflow is idempotent. If it fails, you may retry the job with none cleanup. For instance, it recreates the stg_store_sales desk every time, then deletes the goal desk store_sales with the information for the actual refresh date every time.
The next diagram illustrates the state machine workflow: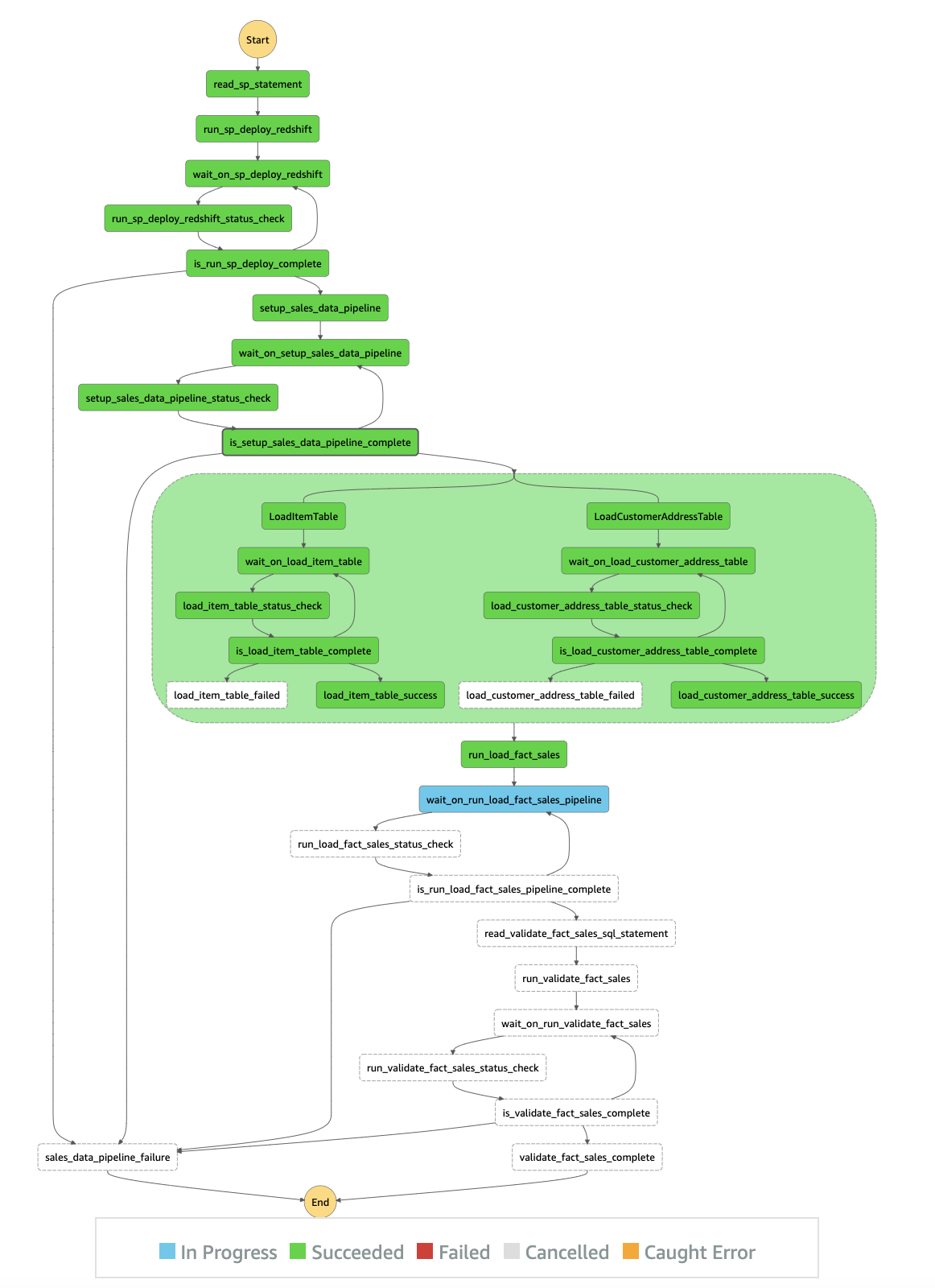
On this instance, we use the duty state useful resource arn:aws:states:::aws-sdk:redshiftdata:[apiAction] to name the corresponding Information API motion. The next desk summarizes the Information API actions and their corresponding AWS SDK integration API actions.
To make use of AWS SDK integrations, you specify the service title and API name, and, optionally, a service integration sample. The AWS SDK motion is all the time camel case, and parameter names are Pascal case. For instance, you should utilize the Step Features motion batchExecuteStatement to run a number of SQL statements in a batch as part of a single transaction on the Information API. The SQL statements could be SELECT, DML, DDL, COPY, and UNLOAD.
Validate the ETL orchestration
All the ETL workflow takes roughly 1 minute to run. The next screenshot exhibits that the ETL workflow accomplished efficiently.
When the complete gross sales knowledge pipeline is full, you could undergo the complete execution occasion historical past, as proven within the following screenshot.
Schedule the ETL orchestration
After you validate the gross sales knowledge pipeline, you could decide to run the information pipeline on a day by day schedule. You possibly can accomplish this with Amazon EventBridge.
- On the EventBridge console, create a rule to run the
RedshiftETLStepFunctionstate machine day by day.
- To invoke the
RedshiftETLStepFunctionstate machine on a schedule, select Schedule and outline the suitable frequency wanted to run the gross sales knowledge pipeline.
- Specify the goal state machine as
RedshiftETLStepFunctionand select Create.
You possibly can affirm the schedule on the rule particulars web page.
Clear up
Clear up the sources created by the CloudFormation template to keep away from pointless price to your AWS account. You possibly can delete the CloudFormation stack by choosing the stack on the AWS CloudFormation console and selecting Delete. This motion deletes all of the sources it provisioned. When you manually up to date a template-provisioned useful resource, you might even see some points throughout cleanup; you want to clear these up independently.
Limitations
The Information API and Step Features AWS SDK integration provides a strong mechanism to construct extremely distributed ETL functions inside minimal developer overhead. Take into account the next limitations when utilizing the Information API and Step Features:
Conclusion
On this submit, we demonstrated find out how to construct an ETL orchestration utilizing the Amazon Redshift Information API and Step Features with AWS SDK integration.
To be taught extra concerning the Information API, see Utilizing the Amazon Redshift Information API to work together with Amazon Redshift clusters and Utilizing the Amazon Redshift Information API.
Concerning the Authors
 Jason Pedreza is an Analytics Specialist Options Architect at AWS with over 13 years of knowledge warehousing expertise. Previous to AWS, he constructed knowledge warehouse options at Amazon.com. He focuses on Amazon Redshift and helps clients construct scalable analytic options.
Jason Pedreza is an Analytics Specialist Options Architect at AWS with over 13 years of knowledge warehousing expertise. Previous to AWS, he constructed knowledge warehouse options at Amazon.com. He focuses on Amazon Redshift and helps clients construct scalable analytic options.
 Bipin Pandey is a Information Architect at AWS. He likes to construct knowledge lake and analytics platforms for his clients. He’s keen about automating and simplifying buyer issues with using cloud options.
Bipin Pandey is a Information Architect at AWS. He likes to construct knowledge lake and analytics platforms for his clients. He’s keen about automating and simplifying buyer issues with using cloud options.
 David Zhang is an AWS Options Architect who helps clients design sturdy, scalable, and data-driven options throughout a number of industries. With a background in software program growth, David is an lively chief and contributor to AWS open-source initiatives. He’s keen about fixing real-world enterprise issues and repeatedly strives to work from the client’s perspective. Be at liberty to attach with him on LinkedIn.
David Zhang is an AWS Options Architect who helps clients design sturdy, scalable, and data-driven options throughout a number of industries. With a background in software program growth, David is an lively chief and contributor to AWS open-source initiatives. He’s keen about fixing real-world enterprise issues and repeatedly strives to work from the client’s perspective. Be at liberty to attach with him on LinkedIn.


