











What can I do right here? Studying new expertise by imagining visible affordances

How do people turn out to be so skillful? Nicely, initially we aren’t, however from infancy, we uncover and observe more and more complicated expertise via self-supervised play. However this play just isn’t random – the kid improvement literature means that infants use their prior expertise to conduct directed exploration of affordances like movability, suckability, graspability, and digestibility via interplay and sensory suggestions. This sort of affordance directed exploration permits infants to be taught each what might be achieved in a given atmosphere and do it. Can we instantiate an identical technique in a robotic studying system?
On the left we see movies from a previous dataset collected with a robotic engaging in numerous duties corresponding to drawer opening and shutting, in addition to greedy and relocating objects. On the precise now we have a lid that the robotic has by no means seen earlier than. The robotic has been granted a brief time frame to observe with the brand new object, after which it will likely be given a objective picture and tasked with making the scene match this picture. How can the robotic quickly be taught to control the atmosphere and grasp this lid with none exterior supervision?
To take action, we face a number of challenges. When a robotic is dropped in a brand new atmosphere, it should be capable of use its prior data to think about doubtlessly helpful behaviors that the atmosphere affords. Then, the robotic has to have the ability to truly observe these behaviors informatively. To now enhance itself within the new atmosphere, the robotic should then be capable of consider its personal success by some means with out an externally offered reward.
If we will overcome these challenges reliably, we open the door for a strong cycle during which our brokers use prior expertise to gather prime quality interplay knowledge, which then grows their prior expertise even additional, constantly enhancing their potential utility!
Our technique, Visuomotor Affordance Studying, or VAL, addresses these challenges. In VAL, we start by assuming entry to a previous dataset of robots demonstrating affordances in numerous environments. From right here, VAL enters an offline part which makes use of this info to be taught 1) a generative mannequin for imagining helpful affordances in new environments, 2) a powerful offline coverage for efficient exploration of those affordances, and three) a self-evaluation metric for bettering this coverage. Lastly, VAL is prepared for it’s on-line part. The agent is dropped in a brand new atmosphere and might now use these discovered capabilities to conduct self-supervised finetuning. The entire framework is illustrated within the determine beneath. Subsequent, we are going to go deeper into the technical particulars of the offline and on-line part.
Given a previous dataset demonstrating the affordances of assorted environments, VAL digests this info in three offline steps: illustration studying to deal with excessive dimensional actual world knowledge, affordance studying to allow self-supervised observe in unknown environments, and conduct studying to realize a excessive efficiency preliminary coverage which accelerates on-line studying effectivity.
1. First, VAL learns a low illustration of this knowledge utilizing a Vector Quantized Variational Auto-encoder or VQVAE. This course of reduces our 48x48x3 photographs right into a 144 dimensional latent area.
Distances on this latent area are significant, paving the way in which for our essential mechanism of self-evaluating success. Given the present picture s and objective picture g, we encode each into the latent area, and threshold their distance to acquire a reward.
In a while, we may also use this illustration because the latent area for our coverage and Q operate.
2. Subsequent, VAL be taught an affordance mannequin by coaching a PixelCNN within the latent area to the be taught the distribution of reachable states conditioned on a picture from the atmosphere. That is achieved by maximizing the probability of the information,
$p(s_n | s_0)$. We use this affordance mannequin for directed exploration and for relabeling targets.
The affordance mannequin is illustrated within the determine proper. On the underside left of the determine, we see that the conditioning picture accommodates a pot, and the decoded latent targets on the higher proper present the lid in several places. These coherent targets will permit the robotic to carry out coherent exploration.
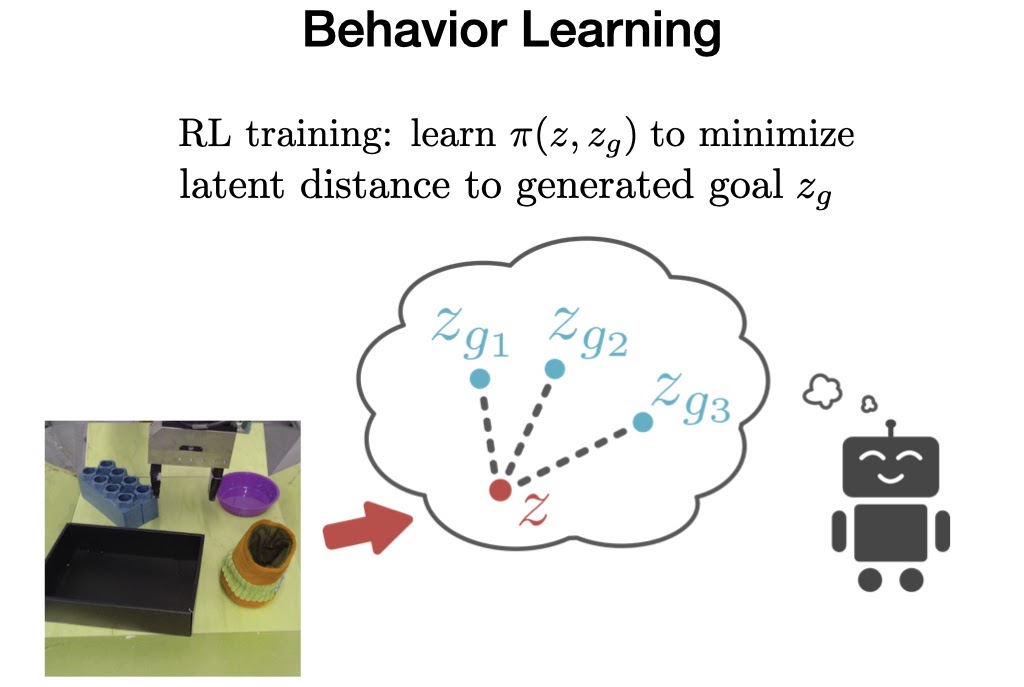
3. Final within the offline part, VAL should be taught behaviors from the offline knowledge, which it could possibly then enhance upon later with additional on-line, interactive knowledge assortment.
To perform this, we prepare a objective conditioned coverage on the prior dataset utilizing Benefit Weighted Actor Critic, an algorithm particularly designed for coaching offline and being amenable to on-line fine-tuning.
Now, when VAL is positioned in an unseen atmosphere, it makes use of its prior data to think about visible representations of helpful affordances, collects useful interplay knowledge by attempting to realize these affordances, updates its parameters utilizing its self-evaluation metric, and repeats the method yet again.
On this actual instance, on the left we see the preliminary state of the atmosphere, which affords opening the drawer in addition to different duties.
In step 1, the affordance mannequin samples a latent objective. By decoding the objective (utilizing the VQVAE decoder, which isn’t truly used throughout RL as a result of we function solely within the latent area), we will see the affordance is to open a drawer.
In step 2, we roll out the educated coverage with the sampled objective. We see it efficiently opens the drawer, in reality going too far and pulling the drawer all the way in which out. However this offers extraordinarily helpful interplay for the RL algorithm to additional fine-tune on and ideal its coverage.
After on-line finetuning is full, we will now consider the robotic on its capability to realize the corresponding unseen objective photographs for every atmosphere.
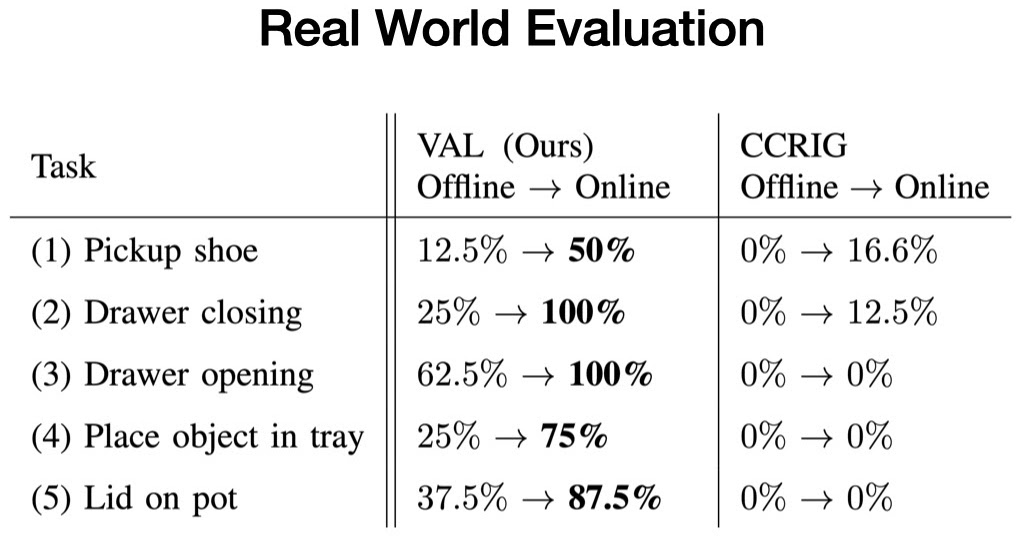
We consider our technique in 5 real-world check environments, and assess VAL on its capability to realize a selected job the atmosphere affords earlier than and after 5 minutes of unsupervised fine-tuning.
Every check atmosphere consists of a minimum of one unseen interplay object, and two randomly sampled distractor objects. As an illustration, whereas there’s opening and shutting drawers within the coaching knowledge, the brand new drawers have unseen handles.
In each case, we start with the offline educated coverage, which solves the duty inconsistently. Then, we acquire extra expertise utilizing our affordance mannequin to pattern targets. Lastly, we consider the fine-tuned coverage, which persistently solves the duty.
We discover that in every of those environments, VAL persistently demonstrates efficient zero-shot generalization after offline coaching, adopted by fast enchancment with its affordance-directed fine-tuning scheme. In the meantime, prior self-supervised strategies barely enhance upon poor zero-shot efficiency in these new environments. These thrilling outcomes illustrate the potential that approaches like VAL possess for enabling robots to efficiently function far past the restricted manufacturing unit setting during which they’re used to now.
Our dataset of two,500 prime quality robotic interplay trajectories, overlaying 20 drawer handles, 20 pot handles, 60 toys, and 60 distractor objects, is now publicly obtainable on our web site.
For additional evaluation, we run VAL in a procedurally generated, multi-task atmosphere with visible and dynamic variation. Which objects are within the scene, their colours, and their positions are randomized per atmosphere. The agent can use handles to open drawers, grasp objects to relocate them, press buttons to unlock compartments, and so forth.
The robotic is given a previous dataset spanning numerous environments, and is evaluated on its capability to fine-tune on the next check environments.
Once more, given a single off-policy dataset, our technique rapidly learns superior manipulation expertise together with greedy, drawer opening, re-positioning, and power utilization for a various set of novel objects.
The environments and algorithm code can be found; please see our code repository.
Like deep studying in domains corresponding to pc imaginative and prescient and pure language processing which have been pushed by massive datasets and generalization, robotics will possible require studying from an identical scale of knowledge. Due to this, enhancements in offline reinforcement studying will likely be crucial for enabling robots to reap the benefits of massive prior datasets. Moreover, these offline insurance policies will want both fast non-autonomous finetuning or solely autonomous finetuning for actual world deployment to be possible. Lastly, as soon as robots are working on their very own, we may have entry to a steady stream of recent knowledge, stressing each the significance and worth of lifelong studying algorithms.
This publish relies on the paper “What Can I Do Right here? Studying New Expertise by Imagining Visible Affordances”, which was offered on the Worldwide Convention on Robotics and Automation (ICRA), 2021. You’ll be able to see outcomes on our web site, and we present code to breed our experiments.
tags: c-Analysis-Innovation

BAIR Weblog
is the official weblog of the Berkeley Synthetic Intelligence Analysis (BAIR) Lab.
BAIR Weblog
is the official weblog of the Berkeley Synthetic Intelligence Analysis (BAIR) Lab.


